




I. Introduction▲
Selon la source : pour certains domaines d'application, il est essentiel de produire des procédures de classification compréhensibles par l'utilisateur. C'est en particulier le cas pour l'aide au diagnostic médical où le médecin doit pouvoir interpréter les raisons du diagnostic. Les arbres de décision répondent à cette contrainte, car ils représentent graphiquement un ensemble de règles et sont aisément interprétables.
Cet article vous guidera pour établir un arbre de décision sous WEKA.
II. Téléchargement et installation▲
II-A. Présentation▲
WEKA est un logiciel libre dédié au Data Mining. Parmi les fonctionnalités qu'il couvre, on trouve les arbres de décision. Selon définition, un arbre de décision est un outil d'aide à la décision et à l'exploration de données. Il permet de modéliser simplement, graphiquement et rapidement un phénomène mesuré plus ou moins complexe. Sa lisibilité, sa rapidité d'exécution et le peu d'hypothèses nécessaires a priori expliquent sa popularité actuelle.
II-B. Téléchargement▲
Le logiciel WEKA peut être téléchargé à partir du site officiel de WEKA ici.
II-C. Installation▲
L'installation de WEKA est facile et rapide, il suffit d'exécuter l'exe précédemment téléchargé. Aucune exigence n'est notée sur le lieu d'installation. Une fois installé, il peut être lancé à partir du menu démarrer en cliquant sur weka 3.4. la fenêtre suivante s'ouvre :

III. Préparation du fichier de données sous format CSV▲
III-A. Extraction des données et export sous format CSV▲
À part les bases de données, les formats de fichiers supportés par WEKA sont le arff et le csv. Le format de fichier le plus utilisé sous WEKA étant le arff. Pour convertir un fichier arff en ce format, il faut passer par des outils ou un programme java qui fait cette conversion. Dans cet article je me contenterai de l'utilisation d'un fichier csv.
Généralement les données sont stockées dans une base de données relationnelle. Plusieurs outils gratuits existent qui permettent d'exporter le résultat d'une requête SQL SELECT dans un fichier csv. Dans mon cas j'utilise SQL-View.
L'arbre de décision à établir nous permettra par exemple de classifier les clients d'une banque s'ils sont des clients à risque ou pas. Cette classification est faite à partir d'autres attributs qu'on appelle des attributs prédicteurs. Dans notre exemple les attributs prédicteurs sont l'âge du client et son revenu. Je suppose par exemple qu'un client à risque est un client qui a au moins un impayé dans ses échéances.
On supposera que notre base de données est composée de deux tables : clients et impayés.
La table clients est composée de :
- idClient : numérique
- age : numérique
- revenu : numérique
La table impayés est composée de :
- idClient : numérique
- Nombre_impayés : numérique
On va créer une nouvelle table: client_risque.
La table client_risque est composée de :
- age : numérique
- revenu : numérique
- aRisque : texte
La table client_risque est remplie à partir des deux dernières tables via un INSERT en faisant une jointure par l'idClient de la manière suivante.
Si le champ Nombre_impayés de la table impayés est supérieur strictement à zéro alors le client est à risque et je mets un 'O' dans le champ aRisque de la table client_risque, sinon je mets un 'N' dans ce champ.
Le résultat d'un SELECT sur la table client_risque ressemblera à ceci :
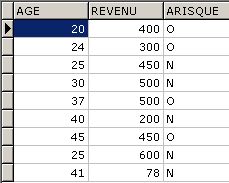
C'est ce résultat du SELECT qu'il faut exporter vers un fichier CSV.
Maintenant notre fichier csv est bien prêt pour utilisation à partir de WEKA.
IV. Établissement de l'arbre de décision▲
IV-A. Connexion au fichier de données CSV▲
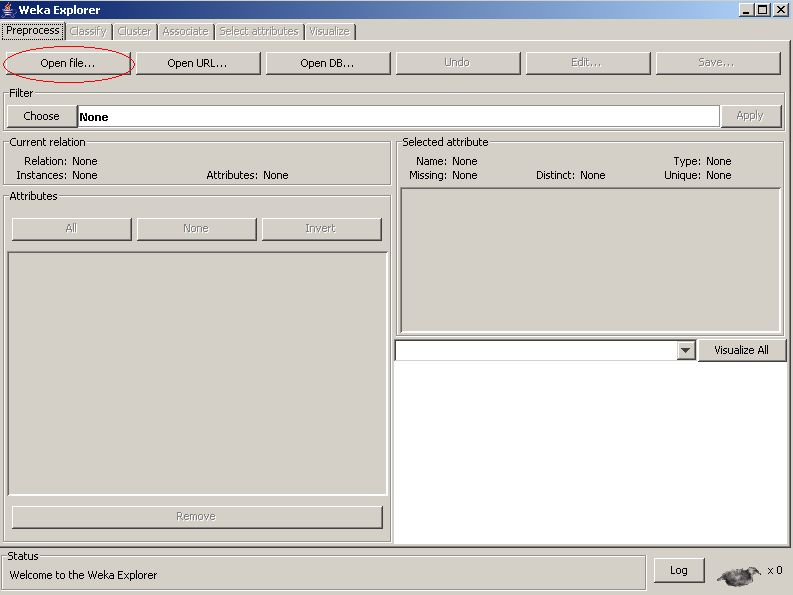
Pour se connecter au fichier précédemment préparé, cliquer sur Explorer sur la première fenêtre apparue lors du lancement de WEKA.

Ensuite, cliquer sur Open file… de l'onglet Preprocess.
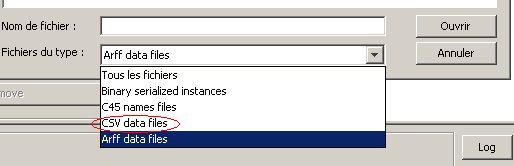
Dans la fenêtre qui s'ouvre choisir le type de fichier csv comme suit :
Et naviguer jusqu'à votre fichier csv et cliquer sur ouvrir. Vous aurez un aperçu du genre :
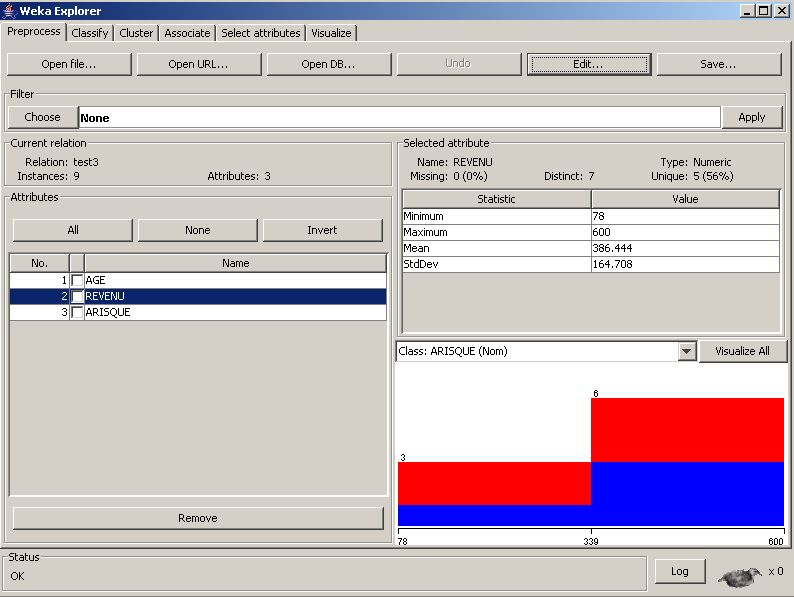
Cet aperçu comporte plusieurs parties. On y trouve :
La partie Current relation :
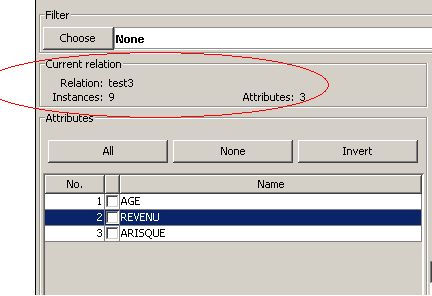
Qui montre :
- Relation : le nom du fichier csv utilisé, dans ce cas c'est test3 ;
- Instances : le nombre d'instances du fichier, dans ce cas c'est 9 ;
- Attributes : le nombre d'attributs traités, dans ce cas c'est 3, à savoir l'âge, le revenu et Arisque.
La partie Attributes :
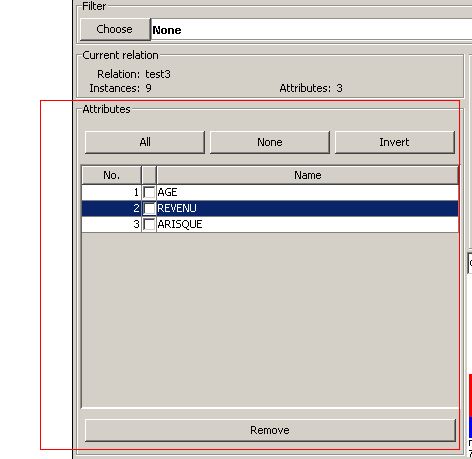
Qui explicite les attributs figurant dans le fichier à traiter. L'utilisateur peut à tout moment cocher un attribut et cliquer sur le bouton Remove pour l'enlever de l'analyse.
Remove permet juste d'enlever un attribut de l'analyse à faire, l'attribut reste intact sur le fichier csv d'origine.
La partie Selected attribute :
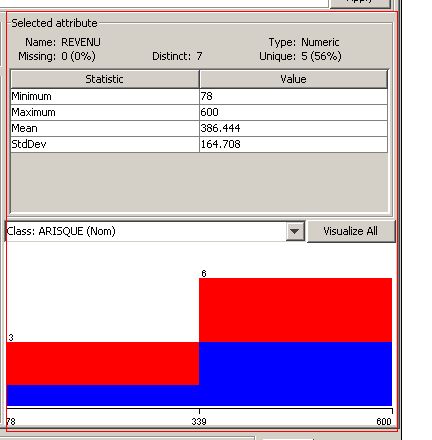
Qui donne des statistiques sur l'attribut sélectionné dans la partie Attributes (le nom de l'attribut, son type : numérique ou texte, nombre d'occurrences distinctes, le minimum et le maximum si c'est un attribut numérique, le nombre d'occurrences si c'est un attribut de type texte…).
Cette partie comporte aussi un graphe en rectangles composés de deux couleurs : le bleu (O : oui à risque) et le rouge (N : non à risque).
On peut bien lire sur ce graphe qu'il y a deux tranches de revenus : en gros des revenus supérieurs ou inférieurs à 339 ( = ( min + max)/2).
Pour les clients ayant un revenu compris entre 78 et 339 :
- un client sur trois est à risque (rectangle bleu occupant 1/3 de la surface comprise entre 78 et 339) ;
- deux clients sur trois sont non à risque (rectangle rouge occupant 2/3 de la surface comprise entre 78 et 339).
Pour les clients ayant un revenu compris entre 339 et 600 :
- trois clients sur six sont à risque (rectangle bleu occupant 1/2 de la surface comprise entre 339 et 600) ;
- trois clients sur six sont non à risque (rectangle rouge occupant 1/2 de la surface comprise entre 339 et 600).
Pour savoir la signification de chaque couleur, il suffit de sélectionner l'attribut à prédire (la classe ARISQUE) dans la partie Attributes. Un graphe s'affiche dans la partie Selected attribute, du genre :
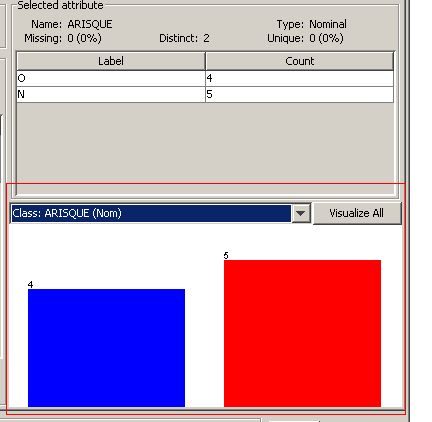
On peut bien remarquer en haut dans la partie Selected attribute qu'il y a quatre occurrences pour la valeur O de l'attribut ARISQUE et cinq occurrences pour la valeur N. Ces deux valeurs sont illustrées par le graphe où l'on constate que la couleur bleue a été assignée pour la valeur O et la couleur rouge pour la valeur N.
IV-B. Établissement de l'arbre de décision▲
Pour établir l'arbre de décision cliquer sur l'onglet Classify, choisir l'option Use training set de Test options comme suit :
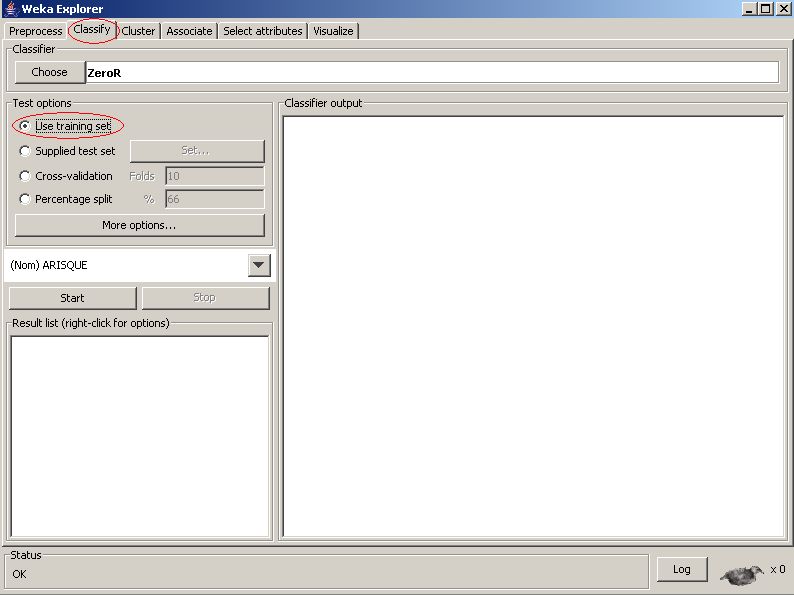
La zone Test options permet de choisir de quelle façon l'évaluation des performances du modèle appris se fera.
- L'option Use training set utilise l'ensemble d'entraînement pour cette évaluation.
- L'option Supplied test set va utiliser un autre fichier.
- Lorsque l'option Cross-validation est sélectionnée, l'ensemble d'apprentissage est coupé en 10 (si Folds vaut 10). L'algorithme va apprendre 10 fois sur 9 parties et le modèle sera évalué sur le dixième restant. Les 10 évaluations sont alors combinées.
- Avec l'option Percentage split, c'est un pourcentage de l'ensemble d'apprentissage qui servira à l'apprentissage et l'autre à l'évaluation.
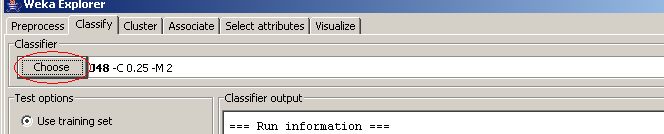
Ensuite, cliquer sur le bouton Choose de Classifier pour choisir un algorithme parmi ceux proposés par WEKA. Dans mon cas je vais utiliser l'algorithme J48.
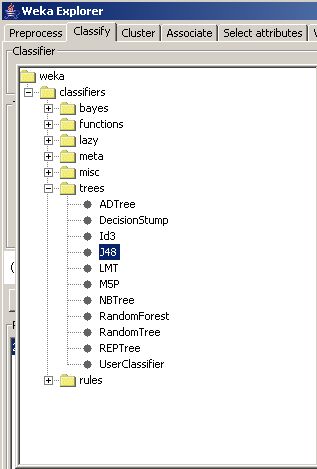
Dans la fenêtre qui s'ouvre, développer le dossier trees et choisir l'algorithme J48 par exemple :
Cliquer sur Start pour effectuer l'analyse.
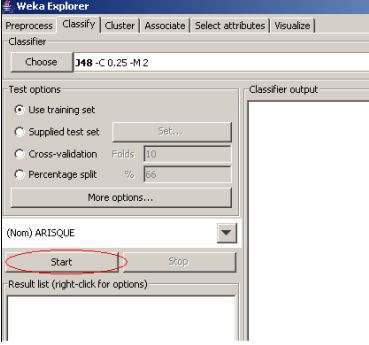
Vous aurez un écran qui ressemble à ceci :
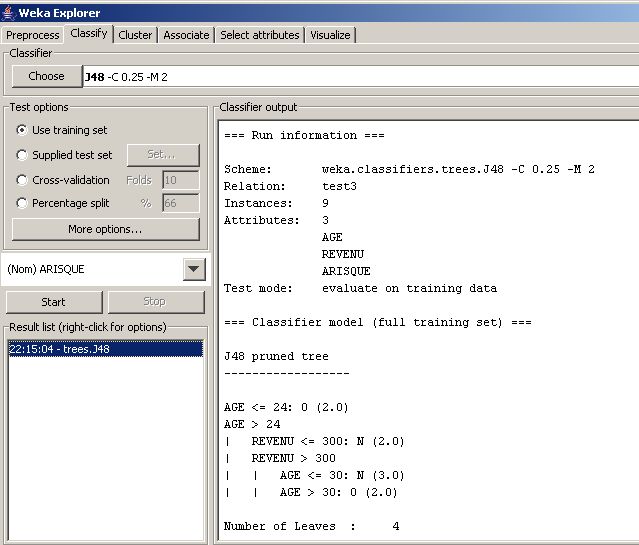
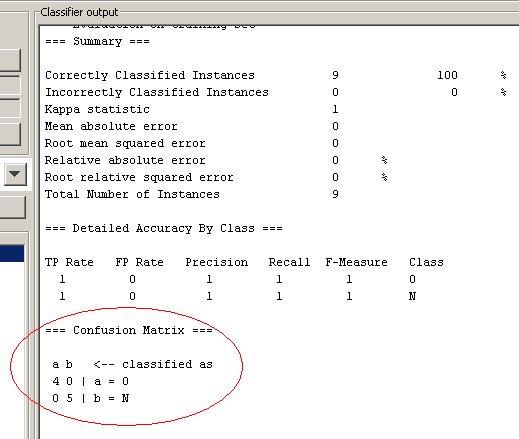
Dans la partie Classifier output vous avez des statistiques sur le fichier exploité, à savoir le nombre d'instances Total Number of Instances de votre fichier, le nombre d'instances correctement classifiées Correctly Classified Instances et incorrectement classifiées Incorrectly Classified Instances et autres statistiques à découvrir !
Sur le même écran, vous avez aussi la matrice de confusion : Confusion Matrix de cette analyse.
Pour afficher l'arbre de décision, cliquer droit dans la partie Result list (right-click for options) :
Lors de ce clic droit, un menu d'options s'affiche comme suit :
Choisir l'option Visualize tree.
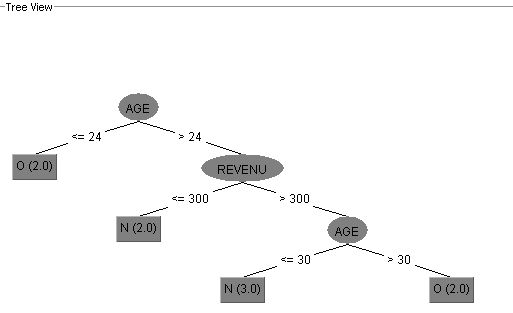
L'arbre de décision s'affiche ressemblant à ceci :
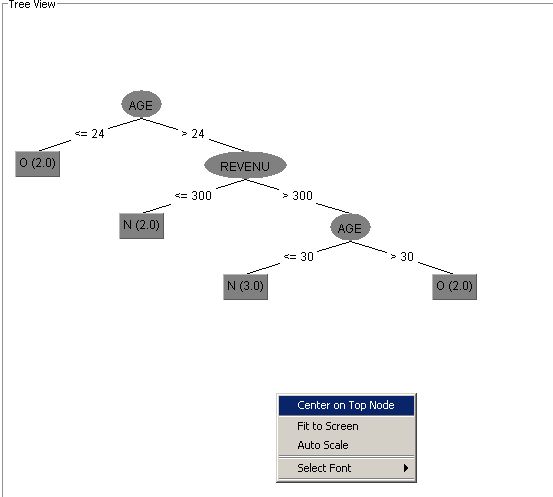
Pour centrer l'affichage de l'arbre, cliquer droit quelque part dans la partie blanche de la fenêtre ouverte et jouer sur les options affichées :
IV-C. Analyse de l'arbre résultat▲
Dans cet exemple on peut analyser le résultat de la manière suivante.
Premièrement, j'ai a deux catégories principales de clients :
- des clients ayant un âge inférieur ou égal à 24 ;
- des clients ayant un âge supérieur strictement à 24.
L'arbre montre que les clients ayant un âge inférieur ou égal à 24 sont tous des clients à risque. Les clients ayant un âge supérieur strictement à 24 sont subdivisés en deux parties :
- des clients ayant un revenu inférieur ou égal à 300 ;
- des clients ayant un revenu supérieur strictement à 300.
L'arbre montre que les clients ayant un âge supérieur strictement à 24 et un revenu inférieur ou égal à 300 sont tous des clients non à risque. Les clients ayant un revenu supérieur strictement à 300 sont subdivisés en deux parties :
- des clients ayant un âge inférieur ou égal à 30 ;
- des clients ayant un âge supérieur strictement à 30.
L'arbre montre que les clients ayant un revenu supérieur strictement à 300 et un âge inférieur ou égal à 30 sont tous des clients non à risque. Les clients ayant un revenu supérieur strictement à 300 et un âge supérieur strictement à 30 sont tous des clients à risque.
V. Conclusion▲
Cet article vous a montré comment établir un arbre de décision sous WEKA à partir d'un fichier CSV. Je suis toujours en train de rechercher comment établir un arbre de décision à partir d'une base de données, je vous ferai part des choses une fois la solution maîtrisée.
VI. Remerciements▲
Un grand merci à Adrien Artero pour ses retours et ses conseils. Je tiens à remercier aussi Fleur-Anne.Blain pour ses corrections.